JVM(七):JVM内存结构
在前几节的文章我们多次讲到 Class 对象需要分配入 JVM 内存,并在 JVM 内存中执行 Java 代码,完成对象内存的分配、执行、回收等操作,因此,如今让我们来走入 JVM,看看 JVM 中的内存结构是如何构造的,下面就让我们一探究竟吧。
内存划分
在本小节中,我们以《Java 虚拟机规范》中的要求,并以当前主流虚拟机 Hotspot VM 为例,详细讲述内存区域中各个模块的划分,了解其各自的用途以及其为何如何划分等。
首先让我们来看一下 Java 虚拟机内存的划分方式。
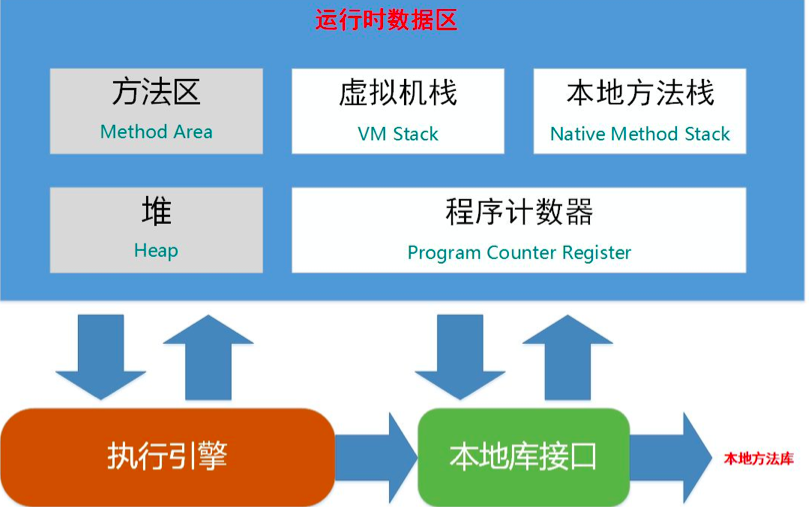
JVM 将内存划分为 5个部分,分别为线程共享的 堆 和 方法区,以及线程私有的 程序计数器,虚拟机栈 和 本地方法栈,下面就让我们针对这 5个区域进行学习,探究其存储数据,生命周期和功能。
程序计数器
是一块较小的内存区域,可以看做是当前线程执行的字节码的行号指示器。在虚拟机概念模型里,字节码解析器就是通过改变这个计数器的值来选取下一条需要执行的字节码,因此其在分支,循环,跳转,异常跳转,线程恢复等功能上都有着大作用。
PS:如果执行的是本地方法,那么这个计数器的值则为空。
虚拟机栈
虚拟机栈也是线程私有的,其内描述的是 Java 方法执行的内存模型,即在每个执行同时创建一个栈帧,栈帧内存储局部变量表,操作数栈,动态链接,方法出口等信息。每一个方法从开始到结束就对应着一个栈帧从入栈到出栈的过程。同时只有位于栈顶的栈帧才是有效的,与其关联的方法称为当前方法,执行引擎的所有字节码指令都只针对当前栈帧进行操作。
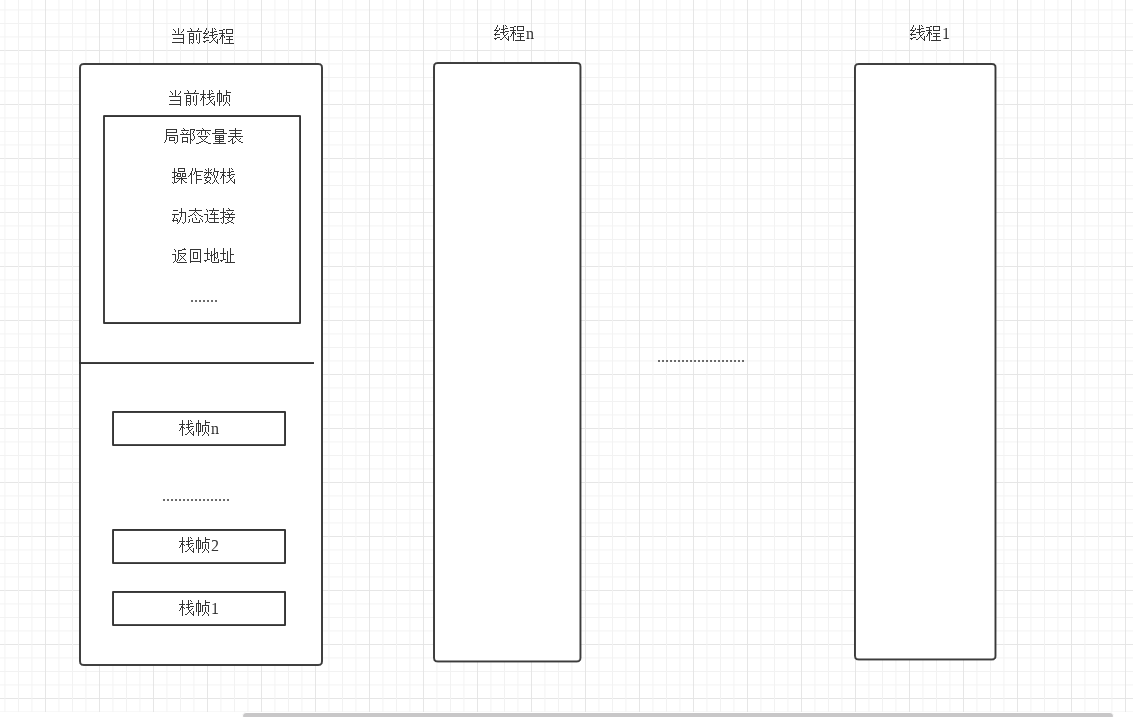
局部变量表
用于存放方法参数和方法内部定义的局部变量,其在 Java 程序被编译为 Class 文件后,就已经确定了所需的最大容量。
其容量以变量槽(slot)为最小单位。因此在使用过程中是通过索引定位来使用局部变量表的,索引范围为 0~~slot 最大值。其中如果执行的是非 static 方法,那么0则默认为 方法所属对象实例引用,对应 Java 关键字的 this。其余参数按照顺序对应 1之后的槽位。
操作数栈
操作栈是一个后入先出的栈,其最大深度在编译时也已经确定。其对应着方法执行过程中,各种字节码指令往操作数栈写入和提取内容,也就是所谓的 入栈/出栈 操作。
也正是操作数栈的存在,因此Java执行引擎也被称为 基于栈的执行引擎,与基于 基于寄存器的执行引擎 形成对比。
Java采取「基于栈的执行引擎」考虑到两点:
- Java是一门跨平台的语言,而不同机器的寄存器实现是不同的,有多又少,不利于统一;
- 为了使 class 文件更加的紧凑,这样设计可以使得大多数指令对齐,并且操作码只占一个字节大小,减少数据量。
动态连接
指向运行时常量池中该栈帧所属方法的引用,通过这个引用可以完成动态调用。
关于方法调用过程中的引用详细解析过程,在日后的「方法调用」中,再具体描述。
返回地址
一个方法在执行完成后都需要返回到方法被调用的位置,让程序继续执行。
在方法正常执行完成退出后,调用者的程序计数器的值就可以作为返回地址存在栈帧中,而在方法异常退出后,返回地址则是通过异常处理器表来确定了。
附加信息
附加信息不是虚拟机规范中必须要求有的,但其允许实现者可以增加一些特殊信息到栈帧中,例如与调试相关的信息,这部分信息取决于具体的虚拟机实现,在这里不再赘述。
本地方法栈
本地方法栈和虚拟机栈的作用类似,区别仅仅是虚拟机栈为虚拟机执行的 Java 方法服务,而本地方法栈则是为 Native 方法服务。其具体实现由虚拟机自行规定。
堆
Java 堆是线程共享的。在一般情况下,堆可以说是 Java 内存中最大的内存区域。其存放了对象实例,几乎所有的对象实例在这里存储。(这里说是几乎,是因为 JIT优化的存在,可能会有对象不在堆上分配,而在栈上进行分配)。
由于目前考虑到垃圾回收算法大部分都是分代算法,因此堆又可以细分为以下几块:
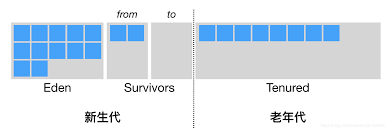
但从其内存本质来看,其并没有详细的区别,都是用来存储对象实例的,这种划分方式是从内存回收的角度来阐述的,因此具体存放逻辑放在「内存回收」中再详细阐述。
方法区
方法区也是线程共享的。其中存放的是被虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据。在HotSpot JDK7 以前的具体实现中,这部分被称为永久代,和堆一起 JVM 管理。但在JDK8之后,这部分已经用 元数据(meta space) 来替代了。此外像字符串常量池也被从这一模块移除,转而用堆来实现。
常量池
JDK7 之后将以前放在方法区的常量池放在堆中进行实现,例如 String 的 intern() 方法,在 JDK8 之后改为如果存在堆中的引用,则直接返回堆中引用,而并不会重新创建对象。
下面让我们来看一下这段代码在 JDK8 下的结果是什么。
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
该代码在JDK8下输出结果为:
false
true
下面就让我们用下图来分析一下是为什么:
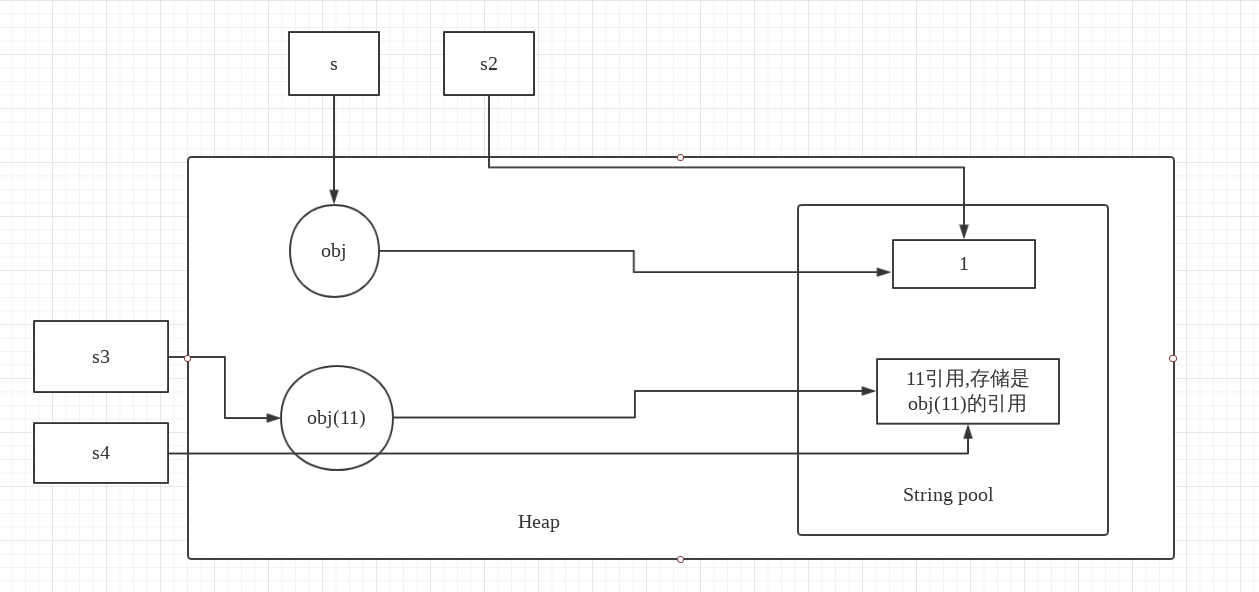
String s = new String("1") 这句生成了两个对象,一个是对象 obj(1),另一个在 String pool 中,是 "1",s 则是指向对象。s.intern() 因为 "1" 在String pool中已经存在,所以直接返回,String s2 = "1",则是直接返回String pool中的引用给s2,最后比较的是两个指向不同地方的引用,因此结果不同。
String s3 = new String("1") + new String("1") 生成了两个对象,一个是对象obj(11),一个是String pool 中的 "1",s3.intern() 判断当 堆中存在对象的时候,则在字符串常量池中保存该对象的引用,然后返回该对象的引用值,String s4 = "11" 则让 s4 指向 String pool 中的值,而 该引用的值就是obj(11)的引用,在最后 System.out.println(s3 == s4) 判断相等的时候,两个引用其实指向的是同一个值,因此返回相等。
直接内存
Direct Memory 不属于 JVM 所管的内存区域,其受到机器总内存的影响。在具体使用中采用一个在 Java 堆中的DirectByteBuffer对象作为这块内存的引用进行操作。
总结
在本文中我们学习了 JVM 在其内部是如何划分区域进行功能协作的。了解了其内部将 JVM 划分哪几个模块,每个模块各自又都有神马作用,其中存储了什么数据,每个模块的不同特性等。
在下文中,我们将讲述对象在堆中的存储,使用方式,了解的Java的 对象模型。

文章在公众号「iceWang」第一手更新,有兴趣的朋友可以关注公众号,第一时间看到笔者分享的各项知识点,谢谢!笔芯!
本系列文章主要借鉴自《深入分析 JavaWeb 技术内幕》和《深入理解 Java 虚拟机-JVM 高级特性与最佳实践》。