一、IPython解释器
字典解析式:
import numpy as np
data = {i:np.random.randn() for i in range(7)}
1、运⾏Jupyter Notebook
Jupyter Notebook需要与内核互动,内核是Jupyter与其它编程语⾔的交互编程协议。Python的Jupyter内核是使⽤IPython。要启动Jupyter,在命令⾏中输⼊jupyter notebook
jupyter notebook # ⾃动打开默认的浏览器(除⾮指定了--no-browser)
#可以在启动notebook之后,⼿动打开⽹⻚http://localhost:8888/。
# 输⼊⼀⾏Python代码。然后按Shift-Enter执⾏。
%pwd # 查看当前的工作目录
2、Tab补全(ipython和jupyter notebook都可以tab补全)
IPython shell的进步之⼀是其它IDE和交互计算分析环境都有的tab补全功能。在shell中输⼊表达式,按下Tab,会搜索已输⼊变量(对象、函数等等)的命名空间。
要补全以下划线开头的变量或方法时,要先输入一个下划线。
实例功能:可以实例系统路径名、函数参数的关键字参数等
3、自省
变量前后使⽤问号?,可以显示对象的信息,如:
b = [1, 2, 3]
b? # 输出如下:
Type: list
String form: [1, 2, 3]
Length: 3
Docstring:
list() -> new empty list
list(iterable) -> new list initialized from iterable's items
print? # 输出如下:
Docstring:
print(value, ..., sep=' ', end='
', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
Type: builtin_function_or_method
在函数名称后面使用"?"会显示函数的文档字符串
在函数名称后面使用"??"会显示函数的源码
?还有⼀个⽤途,就是像Unix或Windows命令⾏⼀样搜索IPython的命名空间。如下:
import numpy as np
np.*load*? # 输出:
np.__loader__
np.load
np.loads
np.loadtxt
np.pkgload
4、%run命令(ipython或者jupyter notebook下)
⽤%run命令运⾏所有的Python程序。假设有⼀个⽂件ipython_script_test.py
%run ipython_script_test.py
这段脚本运⾏在空的命名空间,⽂件中所有定义的变量),都可以在IPython shell中随后访问,除非执行时发生异常
如果想让⼀个脚本访问IPython已经定义过的变量,可以使⽤%run -i
在Jupyter notebook中,你也可以使⽤%load,它将脚本导⼊到⼀个代码格中。
5、中断运⾏的代码
代码运⾏时按Ctrl-C,如果调用了一些编译的扩展模块,要等到控制返回Python解释器才行
6、从剪贴板执⾏程序
在Jupyter notebook可以将代码复制粘贴到任意代码格执⾏
在IPython shell中也可以从剪贴板执⾏。
使⽤%paste和%cpaste函数。%paste可以直接运⾏剪贴板中的代码
%cpaste功能类似,但会给出⼀条提示,使⽤%cpaste,你可以粘贴任意多的代码再运⾏
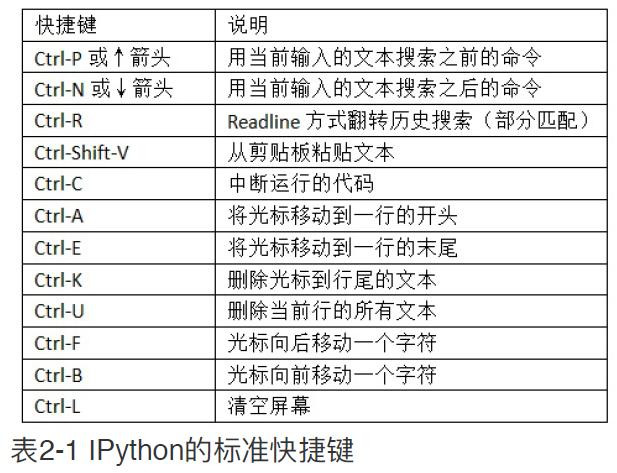
7、键盘快捷键(参见下图所示)
8、魔术命令:在指令前添加百分号%前缀
IPython中特殊的命令(Python中没有)被称作“魔术”命令。
许多魔术命令有“命令⾏”选项,可以通过?查看,例如:
%debug?
魔术函数默认可以不⽤百分号,只要没有变量和函数名相同。这
个特点被称为“⾃动魔术”,可以⽤%automagic打开或关闭。
⽤%quickref或%magic学习下所有特殊命令
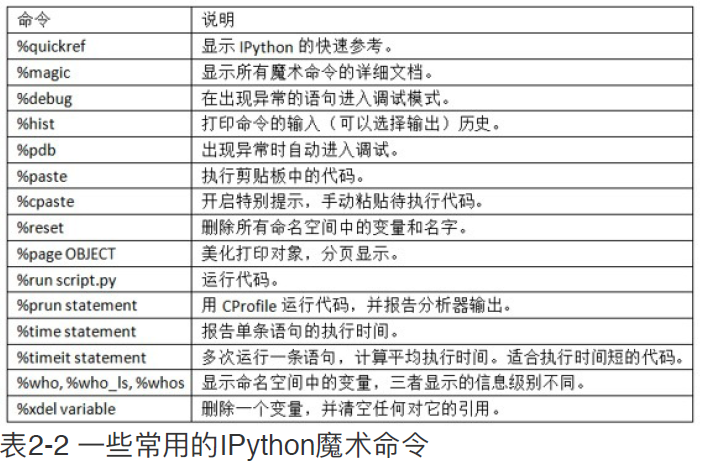
常⽤的IPython魔术命令,参见下图所示:
9、集成Matplotlib
%matplotlib魔术函数配置了IPython shell和Jupyter notebook中的matplotlib。
在JUpyter中,命令有所不同:
%matplotlib inline # 画图演示
import matplotlib.pyplot as plt
plt.plot(np.random.randn(50).cumsum())
二、Python语法基础
1、语⾔的语义:强调的是可读性、简洁和清晰。有些⼈称Python为“可执⾏的伪代码”。
2、使⽤缩进,⽽不是括号:Python使⽤空⽩字符(tab和空格)来组织代码
冒号标志着缩进代码块的开始,冒号之后的所有代码的缩进量必须相同,直到代码块结束。
分号可以⽤来给同在⼀⾏的语句切分:a = 5; b = 6; c = 7
3、万物皆对象
每个数字、字符串、数据结构、函数、类、模块等等,都是在Python解释器的自有“盒⼦”内,它被认为是Python对象。
每个对象都有类型(例如,字符串或函数)和内部数据。
4、注释:任何前⾯带有井号#的⽂本都会被Python解释器忽略。
5、函数和对象⽅法调⽤
⽤圆括号调⽤函数,传递零个或⼏个参数,或者将返回值给⼀个变量
⼏乎Python中的每个对象都有附加的函数,称作⽅法,可以⽤来访问对象的内容。可以⽤下⾯的语句调⽤:
obj.some_method(x, y, z)
函数可以使⽤位置和关键词参数:
result = f(a, b, c, d=5, e='foo')
6、变量和参数传递
当在Python中创建变量(或名字),你就在等号右边创建了⼀个对这个变量的引⽤。
赋值也被称作绑定,我们是把⼀个名字绑定给⼀个对象。变量名有时可能被称为绑定变量。
7、动态引⽤,强类型
与许多编译语⾔(如JAVA和C++)对⽐,Python中的对象引⽤不包含附属的类型。
变量是在特殊命名空间中的对象的名字,类型信息保存在对象⾃身中。
知道对象的类型很重要,最好能让函数可以处理多种类型的输⼊。
可以⽤isinstance函数检查对象是某个类型的实例:
a = 5
isinstance(a, int) # 输出:True
isinstance可以⽤类型元组,检查对象的类型是否在元组中:
a = 5; b = 4.5
isinstance(a, (int, float)) # 输出:True
isinstance(b, (int, float)) # 输出:True
8、属性和⽅法
Python的对象通常都有属性(其它存储在对象内部的Python对象)和⽅法(对象的附属函数可以访问对象的内部数据)。可以⽤obj.attribute_name访问属性和⽅法:
a = 'foo'
a.<Press Tab> # 看变量a有哪些属性和方法
也可以⽤getattr函数,通过名字访问属性和⽅法:
getattr(a, 'split')
<function str.split>
9、鸭⼦类型
可能不关⼼对象的类型,只关⼼对象是否有某些⽅法或⽤途。这通常被称为“鸭⼦类型”,验证⼀个对象是否遵循迭代协议,
判断它是可迭代的。有⼀个__iter__魔术⽅法,其它更好的判断⽅法是使⽤iter函数:如下:
def isiterable(obj):
try:
iter(obj)
return True
except TypeError: # not iterable
return False
isiterable("a string") # 输出:True
isiterable(5) # 输出:False
编写⼀个函数可以接受任意类型的序列(list、tuple、ndarray)或是迭代器。你可先检验对象是否是列表(或是NUmPy数组),如果不是的话,将其转变成列表:如下所示:
if not isinstance(x, list) and isiterable(x):
x = list(x) # 判断x是否是列表对象和或迭代对象,不就是将x转换成列表
11、⼆元运算符和⽐较运算符
加减乘除、比较运算符等都是二元运算符
要判断两个引⽤是否指向同⼀个对象,可以使⽤is⽅法。is not可以判断两个对象是不同的:
a = [1, 2, 3]
b = a
c = list(a) # list总是创建⼀个新的Python列表(即复制)
a is b # 输出:True
a is not c # 输出:True,断定c是不同于a的
使⽤is⽐较与==运算符不同,如下:
a == c # 输出:True
is和is not常⽤来判断⼀个变量是否为None,因为只有⼀个None的实例:
a = None
a is None # 输出:True
下面是常用二元运算符

12、可变与不可变对象
Python中的⼤多数对象,⽐如列表、字典、NumPy数组,和⽤
户定义的类型(类),都是可变的。意味着这些对象或包含的值
可以被修改
字符串和元组,是不可变的
可以修改⼀个对象并不意味就要修改它。这被称为副作⽤。
13、标量类型
Python的标准库中有⼀些内建的类型,⽤以处理数值数据、字符
串、布尔值,和⽇期时间。这些单值类型被称为标量类型,也可称为标量
Python的标量类型:

14、数值类型
Python的主要数值类型是int和float。int可以存储任意⼤的数
浮点数使⽤Python的float类型。每个数都是双精度(64位)的
值。也可以⽤科学计数法表示:
fval = 7.243
fval2 = 6.78e-5 # 科学计数法表示
不能得到整数的除法会得到浮点数
3 / 2 # 输出:1.5
要得到整数除法,可使用地板除//:
3 // 2 # 输出:1
15、字符串
可以⽤单引号或双引号来写字符串
对于有换⾏符的字符串,可以使⽤三引号,''''''和""""""都可以
c = """
This is a longer string that
spans multiple lines
"""
计算c 中的换行符
c.count('
') # 输出:3
Python的字符串是不可变的,不能修改字符串,例如:
a = 'this is a string'
a[10] = 'f' # 报错,
b = a.replace('string', 'longer string') # a的原始值不会变
b # 输出:'this is a longer string'
许多Python对象使⽤str函数可以被转化为字符串,例如:
a = 5.6
s = str(a)
字符串是⼀个序列的Unicode字符,因此可以像其它序列,⽐如列表和元组(⼀样处理)
s = 'python'
list(s) # 字符串转换为列表
反斜杠是转义字符,意思是它被⽤来表示特殊字符,⽐如换⾏符
或Unicode字符。要写⼀个包含反斜杠的字符串,需要进⾏转义:
s = '12\34'
print(s) # 输出:1234
如果字符串中包含许多反斜杠,但没有特殊字符,这样做就很麻烦。可以在字符串前⾯加⼀个r,表明字符就是它⾃身:
s = r'thishas
ospecialcharacters'
s # 输出:'this\has\no\special\characters'
r表示raw。
将两个字符串合并,会产⽣⼀个新的字符串:
a = 'hello '
b = 'michael'
a + b # 输出: hello michael
字符串的模板化或格式化,是另⼀个重要的主题。
字符串对象有format⽅法,可以替换格式化的参数为字符串,产⽣⼀个新的字符串:
template = '{0:.2f} {1:s} are worth US${2:d}'
在这个字符串中,
{0:.2f}表示格式化第⼀个参数为带有两位⼩数的浮点数。
{1:s}表示格式化第⼆个参数为字符串。
{2:d}表示格式化第三个参数为⼀个整数。
要替换参数为这些格式化的参数,传递format⽅法⼀个序列:
template.format(4.5560, 'Argentine Pesos', 1) # 输出如下:
'4.56 Argentine Pesos are worth US$1'
字符串格式化是⼀个很深的主题,有多种⽅法和⼤量的选项,可以控制字符串中的值是如何格式化的。
16、字节和Unicode
在Python 3及以上版本中,Unicode是⼀级的字符串类型,这样可以更⼀致的处理ASCII和Non-ASCII⽂本。在⽼的Python版本中,字符串都是字节,不使⽤Unicode编码。假如知道字符编码,可以将其转化为Unicode。例如:
val = 'chengdu成都'
⽤encode将这个Unicode字符串编码为UTF-8:
val_utf8 = val.encode('utf-8')
val_utf8 # 输出:b'chengduxe6x88x90xe9x83xbd'
type(val_utf8) # 输出:bytes
如果知道⼀个字节对象的Unicode编码,⽤decode⽅法可以解码:
val_utf8.decode('utf-8') # 输出:'chengdu成都'
虽然UTF-8编码已经变成主流,但因为历史的原因,仍然可能碰到其它编码的数据:
val.encode('latin1')
val.encode('utf-16') # 输出:b'xffxfecx00hx00ex00nx00gx00dx00ux00x10bxfdx90'
val.encode('utf-16le') # 输出:b'cx00hx00ex00nx00gx00dx00ux00x10bxfdx90'
⼯作中碰到的⽂件很多都是字节对象,盲⽬地将所有数据编码为Unicode是不可取的。
可以在字节⽂本的前⾯加上⼀个b:
bytes_val = b'this is bytes'
decoded = bytes_val.decode('utf8')
decoded # this is str (Unicode) now
'this is bytes'
17、布尔值:Python中的布尔值有两个,True和False。
⽐较和其它条件表达式可以⽤True和False判断。布尔值可以与and和or结合使⽤:
True and True # 输出:True
False or True # 输出:True
18、类型转换:str、bool、int和float也是函数,可以⽤来转换类型:
s = '3.14159' # 字符串
fval = float(s) # 转float类型
type(fval) # 输出:float
int(fval) # 输出:3
bool(fval) # 输出:True
bool(0) # 输出:False
19、None:None是Python的空值类型。
如果⼀个函数没有明确的返回值,就会默认返回None:
a = None
a is None # 输出:True
b = 5
b is not None # 输出:True
None也常常作为函数的默认参数
另外,None不仅是⼀个保留字,还是唯⼀的NoneType的实例:
type(None) # 输出:NoneType
20、⽇期和时间:Python内建的datetime模块提供了datetime、date和time类型。
datetime类型结合了date和time,是最常使⽤的:
from datetime import datetime, date, time
dt = datetime(2018, 11, 22, 12, 30, 55)
dt.day # 输出:22
dt.minute # 输出:30
根据datetime实例,你可以⽤date和time提取出各⾃的对象:
dt.date() # 输出:datetime.date(2018, 11, 22)
dt.time() # 输出:datetime.time(12, 30, 55)
strftime⽅法可以将datetime格式化为字符串:
dt.strftime('%m/%d/%Y %H:%M') # 输出:'11/22/2018 12:30'
strptime可以将字符串转换成datetime对象:
datetime.strptime('20181122', '%Y%m%d') # 输出:datetime.datetime(2018, 11, 22, 0, 0)
Datetime格式化指令:

当你聚类或对时间序列进⾏分组,替换datetimes的time字段有时
会很有⽤。例如,⽤0替换分和秒:
dt.replace(minute=0, second=0) # datetime.datetime(2018, 11, 22, 12, 0)
因为datetime.datetime是不可变类型,上⾯的⽅法会产⽣新的对象。
两个datetime对象的差会产⽣⼀个datetime.timedelta类型:
dt2 = datetime(2018, 12, 15, 20, 40)
delta = dt2 - dt1
delta # 输出:datetime.timedelta(23, 29345)
type(delta) # 输出:datetime.timedelta
结果timedelta(23, 29345)指明了timedelta将23天、29345秒的编码⽅式。
将timedelta添加到datetime,会产⽣⼀个新的偏移datetime:
dt # 输出:datetime.datetime(2018, 11, 22, 12, 30, 55)
dt + delta # 输出:datetime.datetime(2018, 12, 15, 20, 40)
三、控制流:
Python有若⼲内建的关键字进⾏条件逻辑、循环和其它控制流操作。
1、if、elif和else:if检查⼀个条件,如果为True,就执⾏后⾯的语句:
if后⾯可以跟⼀个或多个elif,所有条件都是False时,还可以添加⼀个else:
如果某个条件为True,后⾯的elif就不会被执⾏。
当使⽤and和or时,复合条件语句是从左到右执⾏:例如:
a = 5; b = 7
c = 8; d = 4
if a < b or c > d:
print('Made it')
在这个例⼦中,c > d不会被执⾏,因为第⼀个⽐较是True:
也可以把⽐较式串在⼀起:
4 > 3 > 2 > 1 # 输出:True
2、for循环:for循环是在⼀个集合(列表或元组)中进⾏迭代,或者就是⼀个迭代器。
for循环的标准语法是:
for value in collection:
# do something with value
可以⽤continue使for循环提前,跳过剩下的部分。
可以⽤break跳出for循环。
break只中断for循环的最内层,其余的for循环仍会运⾏
for i in range(4):
for j in range(4):
if j > i:
break
print((i, j))
如果集合或迭代器中的元素序列(元组或列表),可以⽤for循环将其⽅便地拆分成变量:
for a, b, c in iterator:
# do something
3、While循环
while循环指定了条件和代码,当条件为False或⽤break退出循环,代码才会退出:
4、pass:pass是Python中的⾮操作语句。
代码块不需要任何动作时可以使⽤(作为未执⾏代码的占位符);
因为Python需要使⽤空⽩字符划定代码块,所以需要pass。
5、range:range函数返回⼀个迭代器,它产⽣⼀个均匀分布的整数序列:
list(range(10)) # 输出:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
range的三个参数是(起点,终点,步进):
list(range(5, 0, -1)) # 输出 [5, 4, 3, 2, 1]
range产⽣的整数不包括终点。range的常⻅⽤法是⽤序号迭代序列。
可以使⽤list来存储range在其他数据结构中⽣成的所有整数,默认的迭代器形式通常是你想要的。
虽然range可以产⽣任意⼤的数,但任意时刻耗⽤的内存却很⼩。
6、三元表达式
Python中的三元表达式可以将if-else语句放到⼀⾏⾥。语法如下:
value = true-expr if condition else false-expr
true-expr或false-expr可以是任何Python代码。
三元表达式中的if和else可以包含⼤量的计算,但只有True的分⽀会被执⾏。
虽然使⽤三元表达式可以压缩代码,但会降低代码可读性。