任务一:根据教材参考代码,编写有个简单网络抓包工具,要求核心代码和运行结果截图1-2张。
pcap是一种数据流格式,wireshark软件可以直接把网络数据流变成这种格式。
在Linux里,pcap可以说是一种通用的数据流格式,很多开源的项目都需要用到这种格式的文件。


Global Header (共 24 Byte)
整个数据流文件,只会有一个 Global Header,它定义了本文件的读取规则、最大储存长度限制等内容;
Magic:4Byte:标记文件开始,并用来识别文件自己和字节顺序。0xa1b2c3d4用来表示按照原来的顺序读取,0xd4c3b2a1表示下面的字节都要交换顺序读取。考虑到计算机内存的存储结构,一般会采用0xd4c3b2a1,即所有字节都需要交换顺序读取。
Major:2Byte: 当前文件主要的版本号,一般为 0x0200
Minor:2Byte: 当前文件次要的版本号,一般为 0x0400
ThisZone:4Byte:当地的标准时间,如果用的是GMT则全零,一般都直接写 0000 0000
SigFigs:4Byte:时间戳的精度,设置为 全零 即可
SnapLen:4Byte:最大的存储长度,如果想把整个包抓下来,设置为 ffff 0000,但一般来说 ff7f 0000就足够了【计算机看到的应该是 0000 ff7f 】
LinkType:4Byte:链路类型,常用类型有以下几种,其他的,需要用的时候再查就行了。
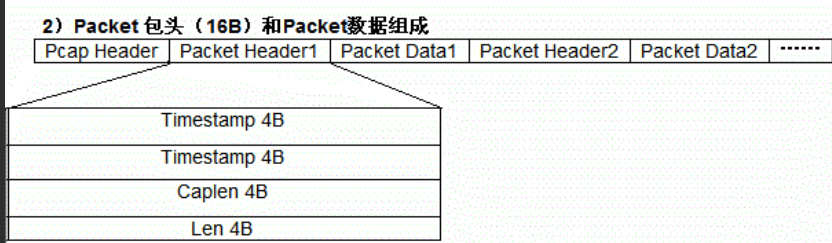
Packet Header(共 16 Byte)
Packet Header可以有多个,每个Packet Header后面会跟着一串Packet Data,Packet Header定义了Packet Data的长度、时间戳等信息。
from scapy.sendrecv import sniff
from scapy.utils import wrpcap
dpkt = sniff(count = 100) #这里是针对单网卡的机子,多网卡的可以在参数中指定网卡
wrpcap("demo.pcap", dpkt)
import struct
fpcap = open('demo.pcap','rb')
ftxt = open('demo.txt','w')
string_data = fpcap.read()
#pcap文件包头解析 ,共计24byte
pcap_header = {}
pcap_header['magic_number'] = string_data[0:4] #标记文件开始,并用来识别文件自己和字节顺序。
pcap_header['version_major'] = string_data[4:6] #当前文件主要的版本号,一般为 0x0200【实际上因为需要交换读取顺序,所以计算机看到的应该是 0x0002】
pcap_header['version_minor'] = string_data[6:8] #当前文件次要的版本号,一般为 0x0400【计算机看到的应该是 0x0004】
pcap_header['thiszone'] = string_data[8:12] #当地的标准时间,如果用的是GMT则全零,一般都直接写 0000 0000
pcap_header['sigfigs'] = string_data[12:16] #时间戳的精度
pcap_header['snaplen'] = string_data[16:20] #最大的存储长度
pcap_header['linktype'] = string_data[20:24]#链路类型
#把pacp文件头信息写入result.txt
ftxt.write("Pcap文件的包头内容如下:
")
for key in ['magic_number','version_major','version_minor','thiszone',
'sigfigs','snaplen','linktype']:
ftxt.write(key+ " : " + repr(pcap_header[key])+'
')
#pcap文件的数据包解析
step = 0
packet_num = 0
packet_data = []
pcap_packet_header = {}
pcap_packet_header_all = []
i =24
while(i<len(string_data)):
#数据包头各个字段
pcap_packet_header['GMTtime'] = string_data[i:i+4] #被捕获时间的高位,单位是seconds
pcap_packet_header['MicroTime'] = string_data[i+4:i+8] #被捕获时间的低位,单位是microseconds
pcap_packet_header['caplen'] = string_data[i+8:i+12]#当前数据区的长度,即抓取到的数据帧长度,不包括Packet Header本身的长度,单位是 Byte ,由此可以得到下一个数据帧的位置。
pcap_packet_header['len'] = string_data[i+12:i+16] #离线数据长度:网络中实际数据帧的长度,一般不大于caplen,多数情况下和Caplen数值相等。
#求出此包的包长len
packet_len = struct.unpack('I',pcap_packet_header['len'])[0]
#写入此包数据
packet_data.append(string_data[i+16:i+16+packet_len])
i = i+ packet_len+16
packet_num+=1
pcap_packet_header_all.append(pcap_packet_header)
#把pacp文件里的数据包信息写入result.txt
for i in range(packet_num):
#先写每一包的包头
ftxt.write("这是第"+str(i)+"包数据的包头和数据:"+'
')
for key in ['GMTtime','MicroTime','caplen','len']:
ftxt.write(key+' : '+repr(pcap_packet_header_all[i][key])+'
')
#再写数据部分
ftxt.write('此包的数据内容'+repr(packet_data[i])+'
')
ftxt.write('一共有'+str(packet_num)+"包数据"+'
')
ftxt.close()
fpcap.close()
生成的pcap文件:
整理生成的txt文档

pcap是一种数据流格式,wireshark软件可以直接把网络数据流变成这种格式。
在Linux里,pcap可以说是一种通用的数据流格式,很多开源的项目都需要用到这种格式的文件。
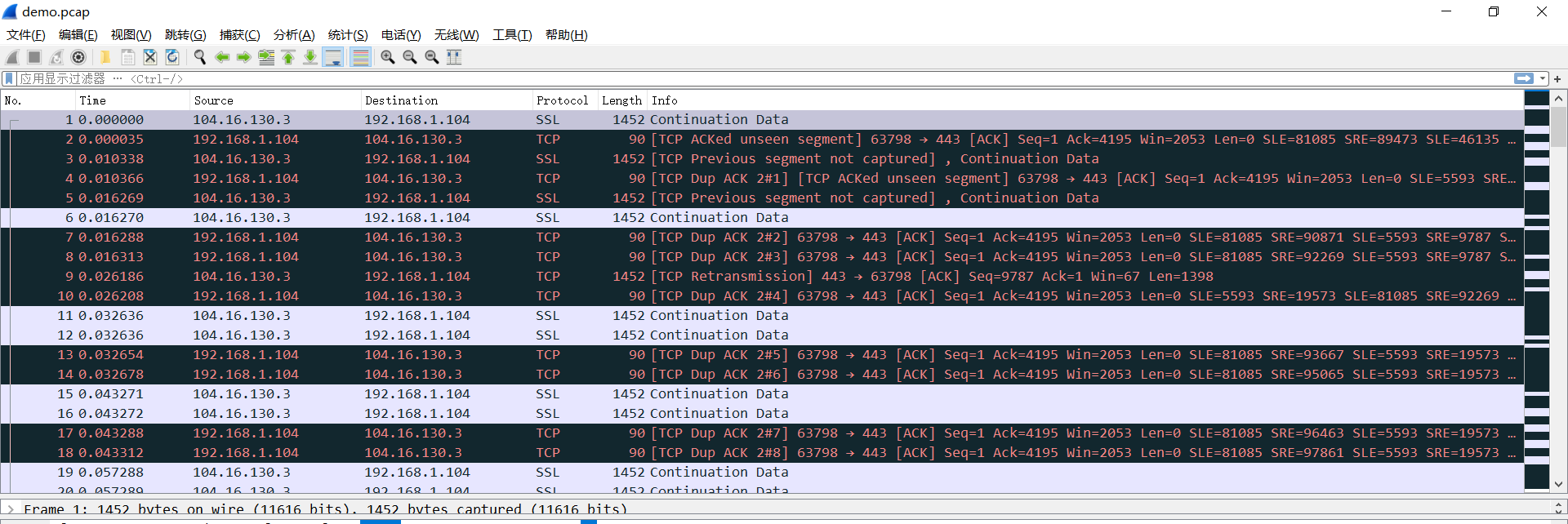
使用wireshark也可以直接打开pacp文件,下图为抓取到的包
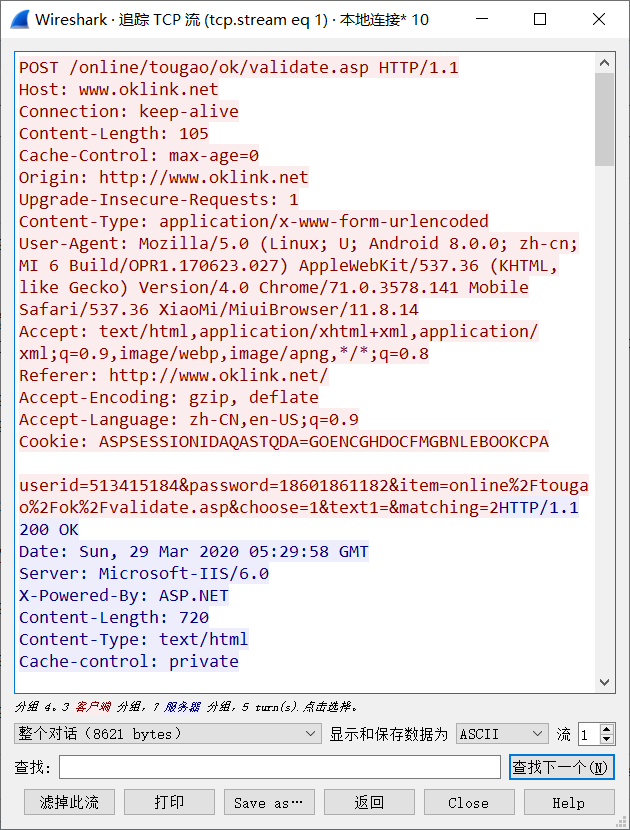
任务二找一个网站或者搭建一个本地网站,登录网站,并嗅探,分析出账号和密码,结果截图1-2张。
现在大多数网站均使用https,密文常常使用md5加密,仅凭抓包无法得到结果。故而寻找了一个文学网站,白鹿书院,此网站自两千年到现在几乎没有改版
随便注册一个账号密码并抓取登录结果如下

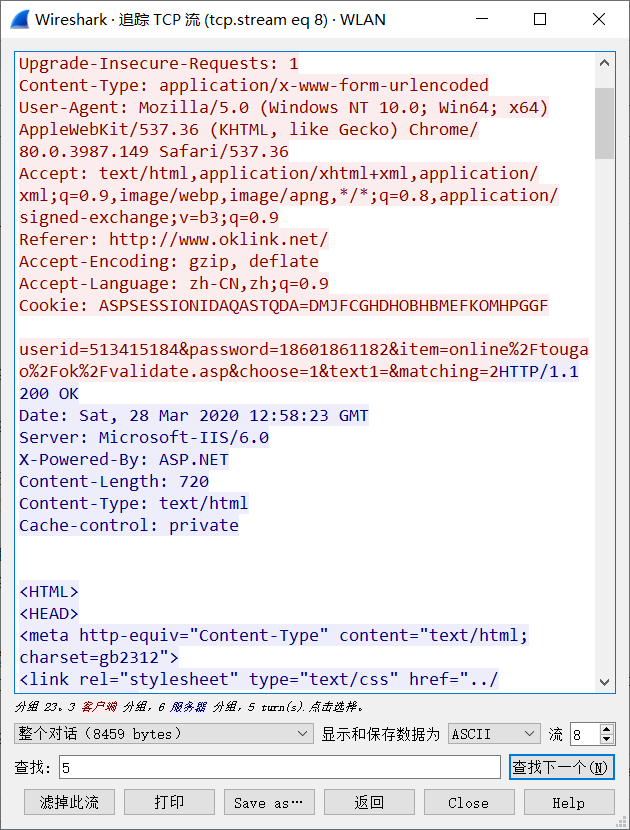
userid和password均使用明文耿直的给出
任务三: 抓取手机App的登录过程数据包,分析账号和密码。可以用邮箱、各类博客、云班课。
目前的商业软件和网站都是密文传输重要数据,故而在手机上登录白鹿书院抓包。
首先打开热点
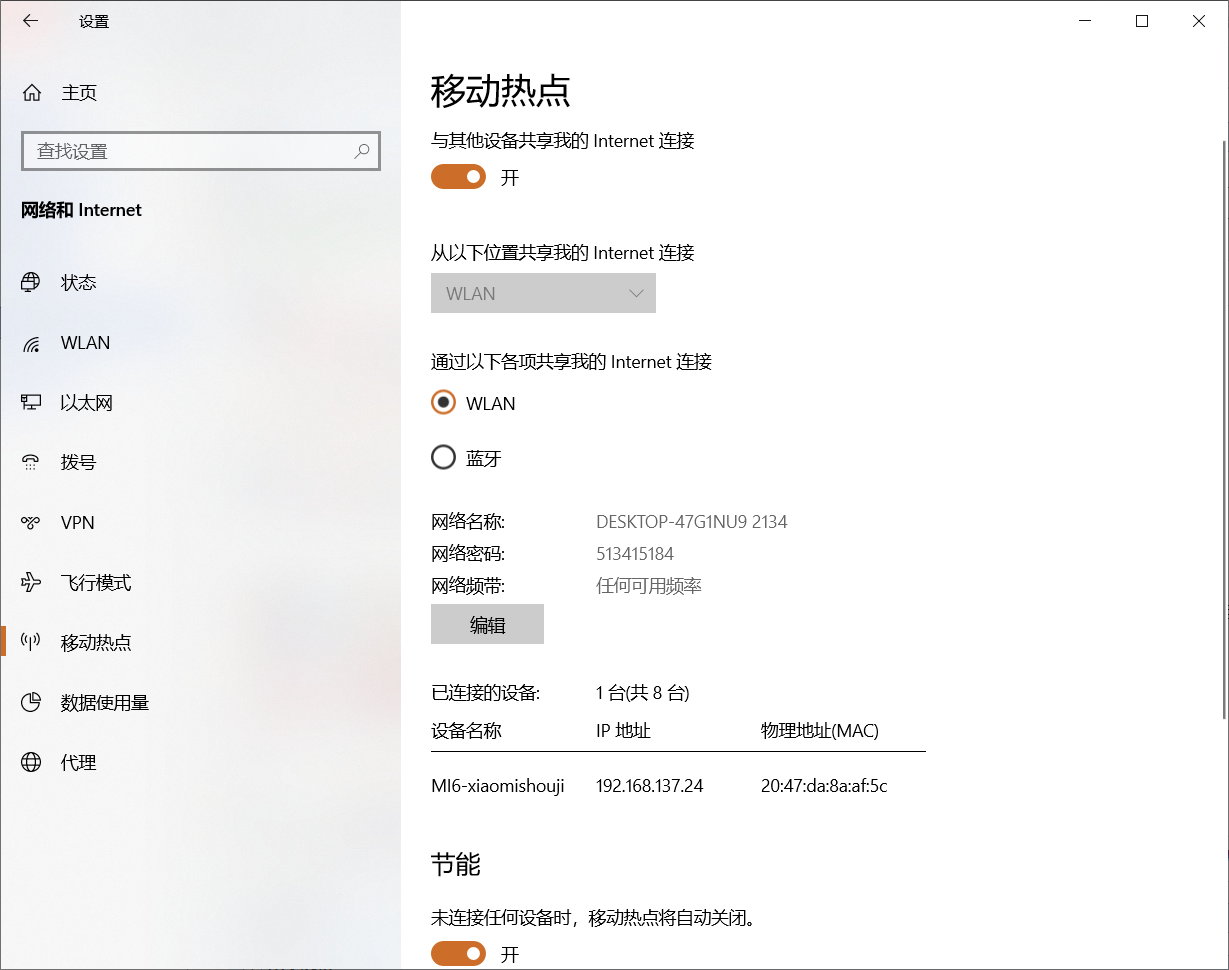
在手机打开网站

抓取结果,192.168.137.24为手机的ip地址

追踪流得到的账号和密码如下