1.1 介绍
开发具有一定价值的符号是人类特有的特征。对于人们来说识别这些符号和理解图片上的文字是非常正常的事情。与计算机那样去抓取文字不同,我们完全是基于视觉的本能去阅读它们。
另一方面,计算机的工作需要具体的和有组织的内容。它们需要数字化的表示,而不是图形化的。
有时候,这是不可能的。有时,我们希望自动化的完成用双手从图像重写文本的任务。
针对这些任务,光学字符识别(OCR)被设计成一种允许计算机以文本形式“阅读”图形化内容的方法,和人类工作的方式相似。虽然这些系统相对准确,但仍然可能有相当大的偏差。即便如此,修复系统的错误结果也远比手工从头开始要更加容易和快速。
就像所有的系统一样,本质上是相似的,光学字符识别软件在准备好的数据集上进行训练,这些数据集提供了足够多的数据用来帮助学习字符间的差异。如果我们想让结果更加准确,那么这些软件如何学习也是非常重要的话题,不过这将是另外一篇文章的内容了。
与其重新造轮或者想出一个非常复杂(但有用)的解决方案,不如我们先坐下来看看已有的解决方案。
1.2 Tesseract
科技巨头 Google 一直在开发一个 OCR 引擎 Tesseract ,它从最初诞生到现在已有数十年的历史。它为许多语言提供了API,不过我们将专注于 Tesseract 的 Java API 。
很容易使用 Tesseract 来实现一个简单的功能。它主要用于读取计算机在黑白图片上生成的文字,并且结果的准确度较好。但这不是针对真实世界的文本。
对于现实世界中,我们最好使用像谷歌 Vision 这样的更高级的光学字符识别软件,这将在另一篇文章中讨论。
1.2.1 Maven依赖
我们只需要简单的添加一个依赖,就可以将引擎引入到我们的项目:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
1.2.2 光学字符识别
使用 Tesseract 毫不费力:
Tesseract tesseract = new Tesseract();
tesseract.setDatapath("E://DataScience//tessdata");
System.out.println(tesseract.doOCR(new File("...")));
我们先实例化一个 Tesseract 实例,然后为已训练好的 LSTM (长短期记忆网络)模型设置数据路径。
数据可以从官方GitHub帐号处下载。
然后我们调用 doOCR() 方法,该方法接受一个文件参数并且返回一个字符串——提取的内容。
让我们给它提供一张有着大而清晰的黑色字符的白色背景图片:

提供这样一张图片会获得完美的结果:
Optical Character Recognition in Java is made easy with the help of Tesseract'
不过这张图片扫描起来过于简单了。它已经被归一化,而且有高分辨率和一致的字体。
让我们来试试在纸上手写一些字符并将该图片提供给应用程序,这将会发生些什么呢:

我们可以立即看到结果的改变:
A411“, written texz: is different {mm compatar generated but
有一些单词十分准确,并且你可以很轻松的辨认出 “written text is different from computer generated” ,但是第一个和最后一个单词差得有点多。
现在,为了让程序使用起来更简单,我们把它转换成一个十分简单的 Spring Boot 应用程序,用更加舒适的图形化界面来展示结果。
1.3 实现
1.3.1 Spring Boot应用程序
首先,从使用Spring Initializr创建我们的项目开始。它包含spring-boot-starter-web和spring-boot-starter-thymeleaf依赖。然后我们手动导入Tesseract:
1.3.2 控制器
该应用程序只需要一个控制器,它将为我们提供两个页面的展示、处理图片上传和光学字符识别功能:
@Controller
public class FileUploadController {
@RequestMapping("/")
public String index() {
return "upload";
}
@RequestMapping(value = "/upload", method = RequestMethod.POST)
public RedirectView singleFileUpload(@RequestParam("file") MultipartFile file,
RedirectAttributes redirectAttributes, Model model) throws IOException, TesseractException {
byte[] bytes = file.getBytes();
Path path = Paths.get("E://simpleocr//src//main//resources//static//" + file.getOriginalFilename());
Files.write(path, bytes);
File convFile = convert(file);
Tesseract tesseract = new Tesseract();
tesseract.setDatapath("E://DataScience//tessdata");
String text = tesseract.doOCR(convFile);
redirectAttributes.addFlashAttribute("file", file);
redirectAttributes.addFlashAttribute("text", text);
return new RedirectView("result");
}
@RequestMapping("/result")
public String result() {
return "result";
}
public static File convert(MultipartFile file) throws IOException {
File convFile = new File(file.getOriginalFilename());
convFile.createNewFile();
FileOutputStream fos = new FileOutputStream(convFile);
fos.write(file.getBytes());
fos.close();
return convFile;
}
}
Tesseract 可以和Java的 File 类一起工作,但是不支持表单上传的 MultipartFile 类。为了便于处理,我们添加了一个简单的 convert() 方法,它将 MultipartFile 对象转换成一个普通的 File 对象。
一旦我们利用 Tesseract 提取出了文本,我们只需将该文本和扫描的图像一起添加到模型当中,然后附加到重定向的展示页面 - result。
1.3.3 展示页面
现在,让我们定义一个包含简单文件上传表单的展示页面:
<html>
<body>
<h1>Upload a file for OCR:</h1>
<form method="POST" action="/upload" enctype="multipart/form-data">
<input type="file" name="file" /><br/><br/>
<input type="submit" value="Submit" />
</form>
</body>
</html>
以及一个结果页面:
<html xmlns:th="http://www.thymeleaf.org">
<body>
<h1>Extracted Content:</h1>
<h2>><span th:text="${text}"></span></h2>
<p>From the image:</p>
<img th:src="'/' + ${file.getOriginalFilename()}"/>
</body>
</html>
运行这个应用程序将会有一个简单的交互界面迎接我们:
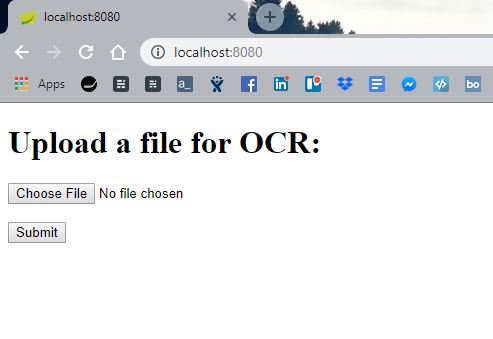
添加一个图片并提交它,屏幕上的结果将会包含提取的文本和上传的图片:
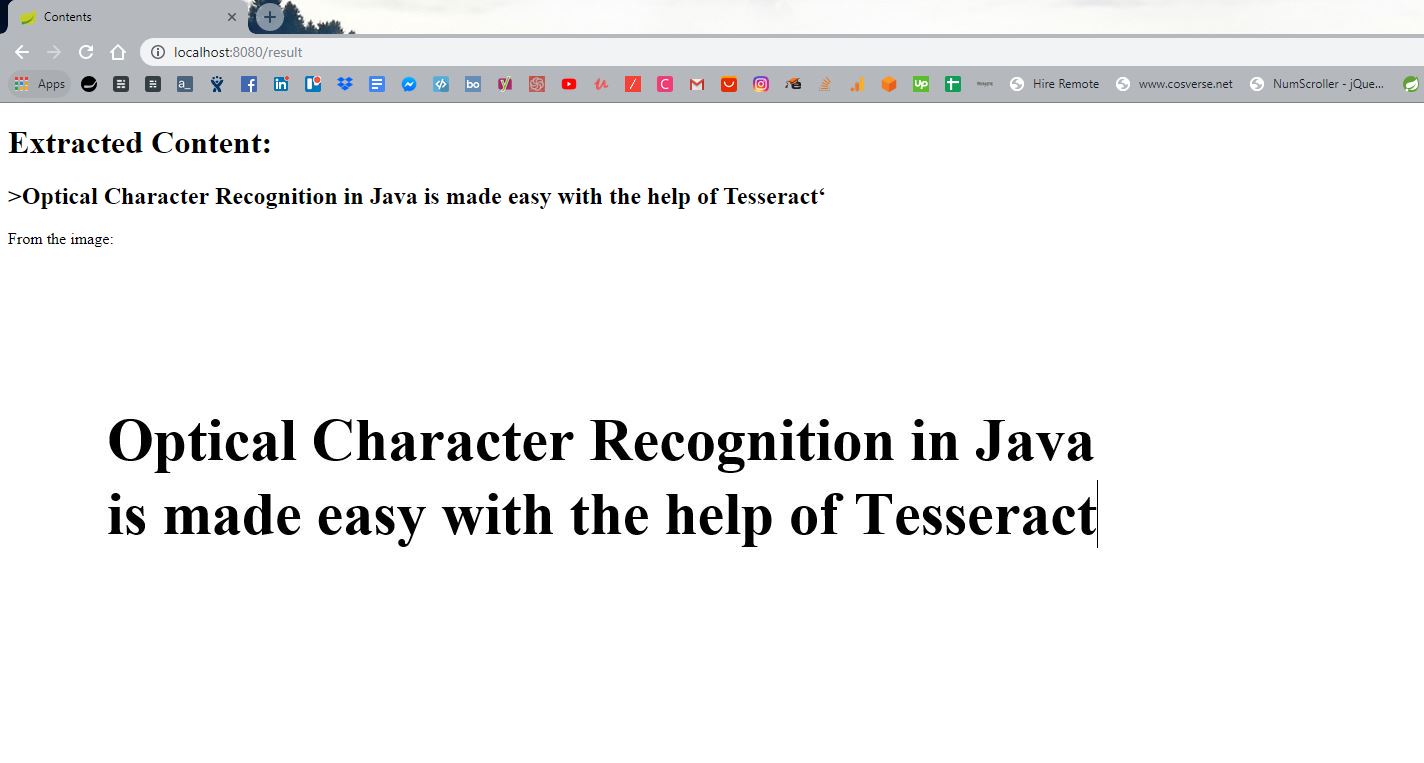
成功了!
1.4 结论
利用谷歌的 Tesseract 引擎,我们搭建了一个十分简单的应用,它接受从表单提交来的图片,从中提取文本内容,最后将结果和图片一起返回给我们。
由于我们只使用了 Tesseract 有限的功能,所以这不是一个特别有用的应用程序。而且该应用程序对于演示目的之外的任何其他用途都过于简单,但是它可以作为一个有趣的工具来实现和测试。
当你想把内容数字化时,光学字符识别可以很快上手,特别是针对文档。他们很容易被扫描,并且提取的内容准确度也较好。当然,为了避免潜在的错误,对结果文档进行校对总是明智的。
8月福利准时来袭,关注公众号 后台回复:003即可领取7月翻译集锦哦~ 往期福利回复:001,002即可领取!
