Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5)
primary首要的 primate原始的 homogeneous均匀的 deformable可变形的
在最近几年中,在PASCAL VOC数据集上测量的目标检测的性能已经趋于平稳。性能最好的方法是复杂的、可理解的系统,这些系统通常将多个底层图像特性与高层上下文结合起来。在这篇论文中,我们提出了一个简单且可扩展的检测算法,其改善后得到的mAP相对于之前在VOC 2012数据集中的最好结果——即mAP为53.3%的效果还要再高30%。
该方法主要包含两个主要的内容:
- 一个是使用了高容量high-capacity的卷积神经网络(CNNs)去得到自底向上的区域划分方案,以定位和分割对象
- 当标记的训练数据不足时,为辅助任务进行有监督的预训练,然后进行特定领域的微调,可以显著提高性能
因为我们将区域划分方案和CNNs结合在一起,所以讲该方法称为R-CNN:Regions with CNN features。我们也将R-CNN和OverFeat进行对比,OverFeat是最近提出的基于一个相似的CNN结构的滑动窗口detector。在200类的ILSVRC2013检测数据集上,我们发现R-CNN比OverFeat有较大的优势。源代码在http://www.cs.berkeley.edu/~rbg/rcnn
1. Introduction
在多种视觉识别任务过去十几年的发展中都是基于SIFT和HOG的使用。但是如果你查看规范识别任务的性能,即在PASCLAL VOC目标检测中,一般都承认在2010-2012年中的进展缓慢,通过构建集成系统和使用成功方法的小变体获得的收益很小
SIFT和HOG是基于块的方向直方图,我们可以粗略地将其与V1中的复杂细胞联系起来,V1是原始视觉通路的第一个皮层区域。但我们也知道,识别发生在下游的几个阶段,这表明可能存在分层的、多阶段的过程来计算特征,而这些特征对视觉识别的信息量更大
Fukushima的 “neocognitron”[19],是一种受生物学启发的层次化和位移不变的模式识别模型,正是这种过程的早期尝试。然而,neocognitron缺乏监督训练算法。以Rumelhart的[33]、LeCun的[26]为基础,证明了反向传播随机梯度下降方法对训练卷积神经网络(CNNs),即扩展了neocognitron的一类模型是有效的。
在1990s年代,CNNs获得广泛使用,但是随着支持向量机的兴起,其就不再受欢迎了。在2012年,Krizhevsky et al. [25]通过在ImageNet Large Scale Visual Recognition Challenge (ILSVRC)大赛上显示出更高的图像分类精度,重新点燃了人们对CNNs的兴趣。他们成功的原因是训练了一个120万张标签图片的大型CNN,加上LeCun的CNN上的一些变化(例如,max(x, 0)校正非线性和“dropout”正则化)。
在2012年ILSVRC研讨会上,关于ImageNet结果的重要性进行了激烈的讨论。核心问题可以归结为:ImageNet上的CNN分类结果在多大程度上可以推广到PASCAL VOC Challenge上的目标检测结果?
我们通过缩小图像分类和目标检测之间的差距来回答这个问题。本文首次证明,与基于简单的类HOG特征的系统相比,基于PASCAL VOC的CNN可以显著提高目标检测性能。为了实现这一结果,我们重点研究了两个问题:用深度网络对目标进行定位,以及用少量带注释的检测数据训练高容量模型。
与图像分类不同,检测需要在图像中定位(可能有很多)对象。一种方法将定位定义为一个回归问题。然而,Szegedy等人[38]和我们自己的研究表明,这种策略在实践中可能并不成功(他们报告了2007年VOC 2007的mAP为30.5%,而我们的方法实现了58.5%)。另一种方法是构建一个滑动窗口检测器。CNNs已经以这种方式使用了至少20年,通常用于约束对象类别,例如人脸[32,40]和行人[35]。为了保持较高的空间分辨率,这些cnn通常只有两个卷积层和池化层。我们还考虑采用滑动窗口方法。然而,在我们的网络中,有5个卷积层,在输入图像中有非常大的接受域(195×195像素)和stride(32×32像素),这使得在滑动窗口范例中精确定位成为一个开放的技术挑战。
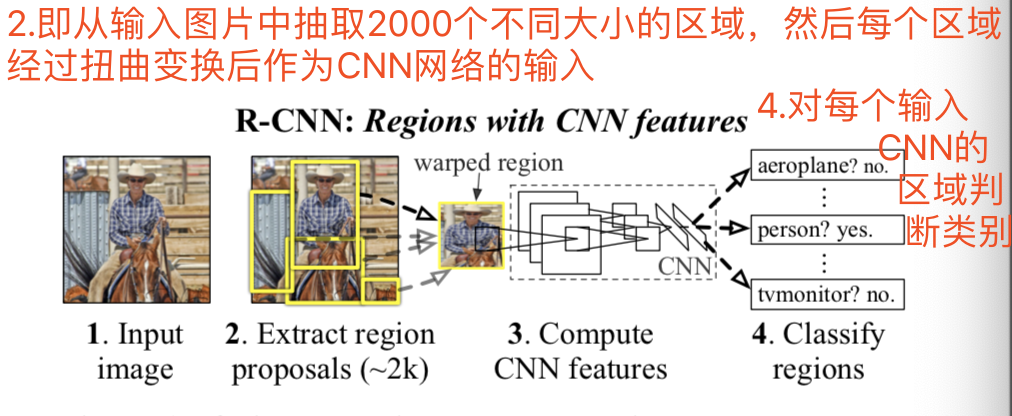
相反,我们通过在“区域识别”范式[21]内操作来解决CNN的定位问题,该范式在对象检测[39]和语义分割[5]两方面都取得了成功。在测试时,我们的方法为输入图像提取了大约2000个与分类无关的区域proposals,接着使用CNN从每个proposal中提取一个固定长度的特征向量,然后使用特定分类的线性svm对每个区域进行分类。我们使用一个简单的技术(仿射图像扭曲)来计算每个区域proposal的固定大小的CNN输入,而不管该区域的形状如何。图1显示了我们方法的概述,并突出显示了我们的一些结果。由于我们的系统将区域proposal与CNN相结合,所以我们将方法命名为R-CNN:Regions with CNN features。如图:
在本文的更新版本中,我们通过在200类的ILSVRC2013检测数据集上运行R-CNN,对R-CNN和最近提出的OverFeat[34]检测系统进行了面对面的比较。OverFeat使用滑动窗口CNN进行检测,是目前ILSVRC2013检测中性能最好的方法。我们显示,R-CNN的表现明显优于OverFeat,其mAP为31.4%,而OverFeat为24.3%。
检测面临的第二个挑战是标记数据稀缺,目前可用的数量不足以训练一个大型CNN。解决这个问题的传统方法是使用无监督的预训练,然后进行有监督的微调(例如,[35])。本文的第二个主要观点是,在大辅助数据集(ILSVRC)上进行有监督的预训练,然后在小数据集(PASCAL)上进行特定领域的微调,是在数据匮乏时学习大容量CNNs的有效范例。在我们的实验中,用于检测的微调将mAP性能提高了8个百分点。经过微调后,我们的系统在VOC 2010上的mAP为54%,而基于HOG的deformable part model(DPM)的mAP为33%[17,20]。我们还指出了Donahue等人同时代的工作,他们指出Krizhevsky的CNN可以作为一个黑盒特征提取器(不需要微调)使用,在包括场景分类、细粒度子分类和领域适应等多个识别任务上都有出色的性能。
我们的系统也相当高效。唯一的类特定计算是一个相当小的矩阵-向量乘积和贪婪的非极大值抑制。这种计算特性来自于跨所有类别共享的特性,并且这些特性的维数也比以前使用的区域特性低两个数量级
了解该方法的失效模式对于改进该方法也至关重要,因此我们报告了来自Hoiem等人的检测分析工具[23]的结果。分析的一个直接结果是,我们证明了一个简单的边界盒bounding-box回归方法显著地避免了错误定位,这是主要的错误模式。
在展示技术细节之前,我们注意到,由于R-CNN对区域进行操作,所以可以很自然地将其扩展到语义分割任务。通过少量的修改,我们在PASCAL VOC的分割任务上也取得了有竞争力的结果,在2011年的VOC测试集上平均分割准确率为47.9%。
2. Object detection with R-CNN
我们的目标检测系统由三个模块组成:
- 第一种方法生成分类独立的区域方案proposals。这些方案proposals定义了一套对我们的探测器有用的候选探测。
- 第二个模块是一个大的卷积神经网络CNN,它从每个区域提取出一个固定长度的特征向量。
- 第三个模块是一组特定于类的线性支持向量机。
其实感觉这个网路就是在一个卷积神经网络前面加上一个region proposals,用来选择图片中的哪个bounding-box作为CNN的输入
在本节中,我们将介绍每个模块的设计决策,描述它们的测试时间使用情况,详细说明如何学习它们的参数,并显示在PASCAL VOC 2010-12和ILSVRC2013上的检测结果。
2.1. Module design
Region Proposals,区域划分方案。最近的许多论文都提供了生成独立分类区域提案的方法。
虽然R-CNN对特定的区域proposal方法是不可知的,但我们使用选择性搜索selective search来与之前的检测工作进行受控比较
Feature extraction,特征提取。我们使用Krizhevsky等人描述的CNN的Caffe[24]实现,从每个区域Proposal中提取4096维的特征向量。通过5个卷积层和2个全连接层正向传播一个平均抽取大小为227×227的RGB图像,同来计算特征。更多的网络架构细节,请参考[24,25]。
为了计算区域Proposals的特征,我们必须首先将该区域的图像数据转换成与CNN兼容的形式(CNN的架构要求输入固定的227×227像素大小)。在任意形状区域的许多可能的变换中,我们选择最简单的方法。无论候选区域的大小或长宽比如何,我们都将它周围的所有像素扭曲到所需的大小。在进行扭曲之前,我们对紧边界框bounding box进行了扩展,以便在扭曲大小处,原始框original box周围有明显的扭曲图像上下文的p像素(我们使用p = 16)。图2显示了扭曲训练区域的随机抽样。附录A讨论了扭曲的替代方法。

2.2. Test-time detection
在测试时,我们对测试图像进行选择性搜索selective search,提取出大约2000个区域的proposal(我们在所有的实验中都使用了选择性搜索的“快速模式”)。我们将每个proposal进行变形,然后通过CNN前向传播去计算特性。然后,针对每个类,我们使用针对该类训练的SVM对每个提取的特征向量进行打分。给定图像中所有得分区域,我们应用贪婪非极大值抑制NMS方法(对每个类独立地),如果一个区域的交并比(IoU)与一个高于学习阈值的得分较高的选定区域重叠,则该区域拒绝该区域,仅使用得分高的那个区域。
Run-time analysis ,实时分析。运行时分析。两个特性使检测效率更高。首先,所有CNN参数在所有类别中共享。其次,与其他常用的方法相比,CNN计算的特征向量是低维的,例如带有大量视觉文字编码bag-of-visual-word encoding的空间金字塔。例如,UVA探测系统[39]使用的特性比我们的要大两个数量级(360k与4k维)。
这种共享的结果是,花在计算区域proposal和特性features(GPU上的13s/图像或CPU上的53s/图像)上的时间被分摊到所有类上。唯一的特定类计算是特征与SVM权重之间的点积计算 和非极大值抑制算法。在实际应用中,一个图像的所有点积都被批量化为一个矩阵-矩阵乘积。特征矩阵一般为2000×4096, SVM权重矩阵为4096×N,其中N为类别数。
该分析表明,R-CNN可以扩展到数千个对象类,而不需要使用诸如哈希等近似技术。即使有100k个类,在现代多核CPU上得到的矩阵乘法也只需要10秒。这种效率不仅仅是使用区域proposal和分享特性的结果。UVA系统,由于其高维特性,将会慢两个数量级,同时只需要134GB的内存来存储100k的线性预测器,而我们的低维特性只需要1.5GB。
同样有趣的是,将R-CNN与Dean等人最近关于使用DPMs和散列hashing[8]进行可伸缩检测的工作进行对比。他们报告了当介绍10k个干扰类别时,在VOC 2007数据集中以一张图片每5分钟的速度计算得到mAP结果大约为16%。使用我们的方法,10k检测器可以在CPU上运行大约一分钟,因为没有进行近似技术,mAP将保持在59%
2.3. Training
Supervised pre-training,监督训练。我们在一个大型辅助数据集(ILSVRC2012分类)上对CNN进行了有区别的预训练,只使用图像级注释(此数据不提供边框bounding-box标签)。使用开源的caffe CNN库[24]进行预训练。简而言之,我们的CNN与Krizhevsky等人的[25]的性能基本匹配,在ILSVRC2012分类验证集上获得了top-1 error比率,高出2.2个百分点。这种差异是由于我们简化了训练过程。
Domain-specific fine-tuning,特定领域的微调。为了使我们的CNN适应新的任务(检测任务)和新的领域(扭曲的proposal窗口),我们只使用扭曲的区域proposal来继续CNN参数的随机梯度下降(SGD)训练。除了用一个随机初始化的(N + 1)-way分类层替换CNN的特定ImageNet的1000-way分类层(其中N是对象类的数量,加上1作为背景)之外,CNN体系结构没有改变,即改变最后一个全连接层,使输出节点数为N+1。对于VOC数据集,N = 20;对于ILSVRC2013数据集,N = 200。我们将所有与ground-truth框重叠并且IoU≥0.5的区域proposal视为该框类的正样本,其余为负样本。我们以0.001的学习率(为初始预训练学习率率的十分之一)开始SGD,这允许在不破坏初始化的同时进行微调。在每个SGD迭代中,我们统一采样32个正窗口(在所有类上)和96个背景窗口,构建一个大小为128的mini-batch。我们倾向于正窗口的抽样,因为与背景相比,它们非常罕见。
Object category classifiers,目标的类别分类器。考虑训练一个二进制分类器来检测车辆。很明显,一个紧密包围汽车的图像区域应该是一个正样本。同样,很明显,与汽车无关的背景区域应该是一个负样本。不太清楚的是,如何给部分与汽车重叠的区域贴上标签。我们使用IoU重叠阈值来解决这个问题,低于这个阈值的区域被定义为负样本。重叠阈值0.3是通过在验证集上的{0,0.1,…,0.5}上的网格搜索选择的。我们发现仔细选择这个阈值非常重要。设置为0.5,就像在[39]中一样,mAP结果减少了5个点。类似地,将其设置为0,mAP减少了4个点。正样本被简单地定义为每个类的ground-truth边界框。
在提取特征并应用训练标签后,我们对每个类优化一个线性SVM。由于训练数据太大,无法存储,我们采用标准的hard negative(困难负样本)挖掘方法[17,37]。hard negative(困难负样本)挖掘收敛很快,在实际中,当只有一个负样本通过所有的图像后,mAP将停止增长。
在附录B中,我们讨论了为什么在微调和支持向量机训练中对正样本和负样本的定义不同。我们还讨论了训练检测支持向量机所涉及的权衡,而不是简单地使用微调后的CNN的最终softmax层的输出。
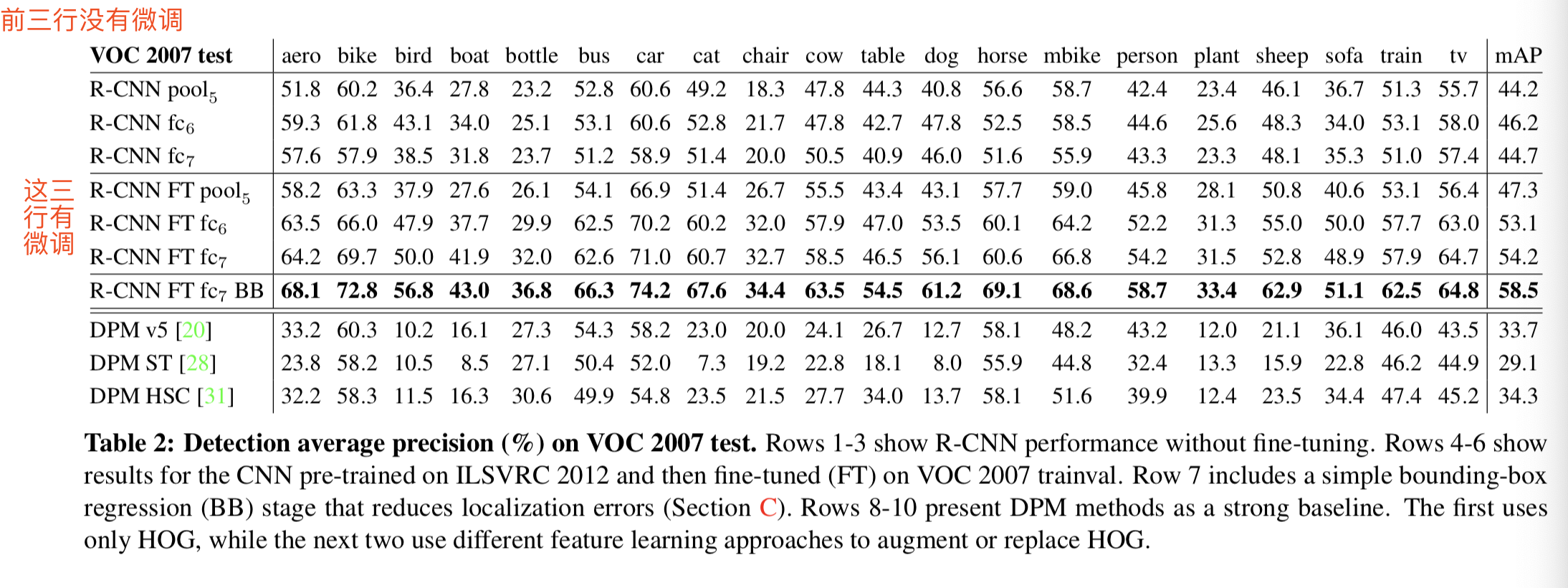
3.2. Ablation studies
Performance layer-by-layer, without fine-tuning.这个研究说明CNN网络更多的表达能力是来自于他的卷积层,而不是其全连接层
Performance layer-by-layer, with fine-tuning.这个研究说明微调对全连接层起的作用比对卷积层起的作用大,能够很好地改善全连接层的特征表达能力
3.3. Network architectures
表3显示了Simonyan和Zisserman[43]最近提出的16层深度网络对VOC 2007测试的结果。在最近的ILSVRC 2014年分类挑战中,该网络是表现最好的网络之一。该网络结构均匀,由13层3×3个卷积核组成,中间穿插5个max pooling层,顶部为3个全连接层。我们把这个网络称为OxfordNet的“O-Net”,即VGGnet,16层,13个卷积层和3个全连接层;把TorontoNet的基准称为“T-Net”,即Alexnet,8层,5个卷积层和3个全连接层
在O-Net的效果比T-net的好,但是缺点就是O-net的时间更长:

与SPP-net做对比:
参考https://blog.csdn.net/qq_35451572/article/details/80273222
一次特征提取
RCNN是多个regions+多次CNN+单个pooling,而SPP则是单个图像+单次CNN+多个region+多个pooling

算法流程:
- 首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
- 特征提取阶段。这一步就是和R-CNN最大的区别了,同样是用卷积神经网络进行特征提取,但是SPP-Net用的是金字塔池化。这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度是大大地快啊。江湖传说可一个提高100倍的速度,因为R-CNN就相当于遍历一个CNN两千次,而SPP-Net只需要遍历1次。
- 最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
在特征提取上,速度提升了好多,R-CNN是直接从原始图片中提取特征,它在每张原始图片上提取2000个Region
Proposal,然后对每一个候选区域框进行一次卷积计算,差不多要重复2000次,而SPP-net则是在卷积原始图像之后的特征图上提取候选区域的特征。所有的卷积计算只进行了一次,效率大大提高。
缺点
SPP已有一定的速度提升,它在ConvNet的最后一个卷积层才提取proposal,但是依然有不足之处。和R-CNN一样,它的训练要经过多个阶段,特征也要存在磁盘中,另外,SPP中的微调只更新spp层后面的全连接层,对很深的网络这样肯定是不行的。